GPT-Image-1完全ガイド:AIを使ってあなたの頭の中のイメージを現実のものにしよう

こんな瞬間を経験したことはありませんか——
頭の中に素晴らしい映像が浮かんでも、ネット上でどこにも適切な素材が見つからない。イベントのポスターを作りたいのに、デザインソフトを前にぼんやりと、どこから始めればいいかわからない。クライアントへの提案用のビジュアルが必要なのに、予算的にプロのフォトグラファーを雇えない……
これらの悩みに、今新しい解決策が登場しました。OpenAIが2025年にリリースしたGPT-Image-1は、普通の人々と画像制作の関係を静かに変えつつあります。これは複雑な呪文を暗記する必要があるツールではなく、本当に「人の言葉を理解する」AI画家なのです。

この記事では、ゼロからこのツールが実際に何ができるのか、そして効果的に使う方法をご紹介します。
他のAI画像生成ツールと何が違うのか?
市場にはAI画像生成ツールが数多くありますが、GPT-Image-1の特別な点は何でしょうか?
簡単に言えば、GPT-4o——つまりChatGPTのように会話したり、文章を書いてくれる大規模言語モデルをベースに構築されています。これは何を意味するのでしょうか?人間のアシスタントと話すのと同じくらい自然にコミュニケーションできるということです。
例を挙げましょう。以前は、こんなプロンプトを書く必要がありました:
"portrait, female, 25 years old, realistic, 8k, detailed skin texture, studio lighting, white background"
今では、こう言うだけで済みます:
「25歳くらいのキャリアウーマンの肖像画を生成してください。自信に満ち、有能そうな雰囲気で、背景はシンプルに。」
「自信に満ち、有能そう」がどんな表情や姿勢に対応するか理解し、「シンプル」がどんな背景処理を必要とするか解釈できます。この理解力の違いを体験したら、もう戻れません。
特に注目すべき機能がいくつかあります:
実際に使える文字レンダリング。 以前、AIに画像内に文字を入れるよう頼むと、文字化けしたものが出てきました。GPT-Image-1は、要求した文字を正確に画像内に配置できます——店舗看板、商品ラベル、ポスターのスローガンなど、すべてクリアに表現されます。
既存画像の編集にも対応。 画像をアップロードして「背景をビーチに変えて」や「この人に眼鏡をかけさせて」と伝えると、主要被写体を保ったまま局所的な調整を行います。
非常に幅広いスタイル対応。 フォトリアルから水彩イラスト、サイバーパンクから水墨画まで——すべて対応できます。どのモデルがどのスタイルを得意とするか研究する必要はありません。一つのツールで全部できます。
効果的なプロンプトの書き方は?
多くの人がAI画像生成を「ガチャ」のようなものだと考えています——運が良ければいい結果が出る、と。実際はそうではありません。鍵は、ニーズをどう説明するかです。
GPT-Image-1の利点は、本当にあなたの言葉を理解できることです。だから必要なのは、キーワードを詰め込むことではなく、その画像を明確に「言葉で表現する」ことです。
実際に効果があるシンプルなフレームワークをまとめました:
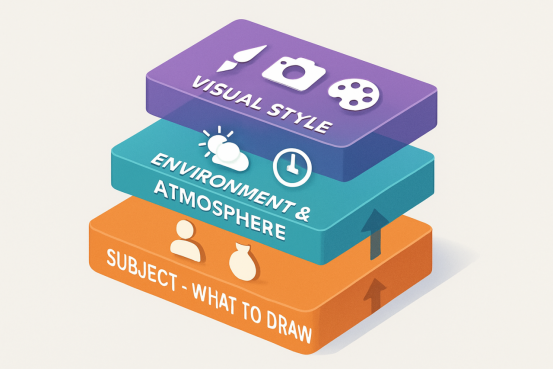
第一層:何を描くか明確に述べる
これは基本ですが、最も問題が起きやすい部分でもあります。
曖昧な描写:「通りにいる女の子」
具体的な描写:「ポニーテールの女子高生、制服を着て、リュックを背負い、横断歩道を渡っている。表情は物思いにふけったような、少しぼんやりとした感じ」
違いは何でしょう?後者は年齢、服装、動作、感情を提供しており、AIは物語性のある画像を生成できます。単なる空虚な人型ではありません。
第二層:環境と雰囲気を設定する
人物だけでは不十分です。シーンが画像全体の情緒的なトーンを決定します。
以下のような情報を追加できます:
- 時間帯(早朝、夕暮れ、深夜)
- 天気(雨、曇り、晴れ)
- 具体的な場所の特徴(東京の渋谷交差点、北京の古い胡同、北欧風カフェ)
- 全体的な雰囲気(温かい、緊張感のある、孤独な、賑やかな)
例えば、先ほどの例を拡張すると:
「ポニーテールの女子高生、制服を着て、リュックを背負い、横断歩道を渡っている。表情は物思いにふけったような、少しぼんやりとした感じ。シーンは夕暮れの東京の街頭、雨上がりで、路面に水たまりが光を反射している。周りは帰宅途中の人々、ネオンサインが灯り始めている。全体的な雰囲気は、かすかな憂鬱さを帯びている。」
第三層:ビジュアルスタイルを指定する
同じ内容でも、異なるスタイルで表現すると、全く違う結果になります。
以下の方向性を検討できます:
- 芸術運動:印象派、浮世絵、ポップアート
- 特定のアーティストスタイル:宮崎駿アニメ風、モネの光の扱い
- 媒体と素材:油絵の質感、鉛筆スケッチ、水彩のぼかし、映画のスチル
- 技術パラメータ:シネマティッククオリティ、柔らかい被写界深度、ドラマチックなサイドライティング
先ほどの例をさらに拡張すると:
「…全体的な雰囲気は、かすかな憂鬱さを帯びている。ビジュアルスタイルは新海誠アニメの美学を参考に、彩度をやや高めに、光と影の処理に映画的な感覚を持たせる。」
さまざまな業界での実際の使用例
ゲームキャラクターコンセプトデザイン
あなたは、ポストアポカリプスをテーマにしたRPGを制作しているインディーゲーム開発者で、NPCキャラクターをデザインする必要があります。
サンプルプロンプト:
「ポストアポカリプス荒廃世界スタイルの女性キャラクターの全身キャラクター設定図。28歳くらい、ショートヘア、左頬に古い傷跡がある。改造された古い軍服ジャケットを着ており、片方の袖が一部破れている。腰には自作の工具キットと錆びたバールがぶら下がっている。破損したカーゴパンツ、ブーツは布で補強されている。表情は警戒しているが凶暴ではなく、目には物語がある。立ち姿はやや斜めで、いつでも行動に移れる様子。背景は純粋な灰色で、後で切り抜きしやすいように。スタイルは『The Last of Us』のリアルなアート方向を参考にするが、やや イラスト寄りに。」
ポイント: キャラクターの世界観背景、具体的な服装の詳細、外見から伝わる性格、実用的な背景設定(切り抜きしやすい)。
教育教材用イラスト
あなたは教師で、「光合成」の授業用の図解を準備しています。
サンプルプロンプト:
「植物の光合成プロセスを示す科学イラスト。画面中央は緑の葉の断面図で、葉緑体の構造が見える。矢印を使って、太陽光が入る、二酸化炭素の吸収、酸素の放出、グルコースの生成のプロセスをラベル付けする。スタイルは教科書のイラストに似せて、色は明るくクリアに、各部分の名称を示す適切なテキストラベルを付ける。」
ポイント: 構造が明確、ラベル付けが正確——これこそGPT-Image-1の文字レンダリング能力が活きる場面です。
建築ビジュアライゼーション
あなたはインテリアデザイナーで、クライアントに和風侘び寂びスタイルのリビングルームのコンセプトを提示する必要があります。
サンプルプロンプト:
「和風侘び寂びスタイルのリビングルームを示すインテリアデザインのレンダリング。約30平方メートル、天井が高く、小さな中庭に面した掃き出し窓がある。全体的な色調は温かみのあるオフホワイト、ナチュラルウッド、グレーブラウンのトーン。壁は微妙な質感のある漆喰仕上げ、床は明るい色のテラゾー。家具は最小限:低い木製のコーヒーテーブルと、その横に2つのリネン色の座布団。隅には粗い陶器の花瓶があり、裸の枝が一本挿してある。黒い細いフレームの掃き出し窓から、苔、砂利、小さなカエデの木がある中庭が見える。午後3-4時の自然光が窓から斜めに差し込み、床に窓枠の影を落としている。全体的な雰囲気は静かで、余白があり、呼吸できる感じ。部屋の入り口から窓の方向を見る視点で、やや斜めのアングル。高精細フォトリアリスティック品質、建築雑誌の写真のように。」
ポイント: 空間スケール、素材の詳細、家具の配置、光の時間と方向、視点の角度——この情報が完全であればあるほど、AIはあなたのデザインビジョンを正確に実現できます。

児童絵本イラスト
あなたは絵本作家で、子ぎつねの冒険物語を創作しており、あるページのイラストが必要です。
サンプルプロンプト:
「児童絵本スタイルのイラスト。小さなキツネが巨大な古いオークの木の下に立ち、枝にぶら下がっている不思議なランタンを見上げている。キツネはオレンジ赤色で、丸くて好奇心に満ちた目、ふわふわの尾。古いオークは非常に太く、樹皮のパターンが顔のように見え、この木が生きていて知性を持っているような印象を与える。ランタンは暖かい黄色の光を放ち、夕暮れの森で特に目立つ。地面は落ち葉とキノコで覆われており、遠くの木々のシルエットは夕日に照らされて深い青色。全体のスタイルは手描きの水彩感、色は暖かいが刺激的ではなく、柔らかい筆致で、かすかな紙の質感。雰囲気は温かみがあり少し神秘的、3-6歳児向けの絵本に適している。」
ポイント: 明確な対象年齢層、キャラクターの感情と性格、物語性のあるシーン(物語の中の一瞬)、印刷と子供の美的感覚に適したスタイル。
結婚式招待状イラスト
友人があなたに結婚式の招待状のデザインを依頼し、ヴィンテージでロマンチックなイラストが必要です。
サンプルプロンプト:
「招待状デザイン用のヴィンテージロマンチックスタイルの結婚式イラスト。画像は横顔のカップルのシルエットでキスをしており、優雅な輪郭。彼らはヨーロッパスタイルの庭園のアーチの下に立ち、アーチには満開のバラとツタが覆っている。背景は夕焼けの残照、空はオレンジピンクから淡い紫へのグラデーション。地面には花びらが散っている。全体のスタイルはヴィンテージイラストのように、20世紀初頭のヨーロッパの版画のような感じで、繊細な装飾線と柔らかい色。画像の周囲には後でテキストを追加できるように余白を残す。暖色調でロマンチックだが俗っぽくない。アーチの頂点にはハート型の装飾があり、そこに'L & M'の文字を書ける。」
ポイント: 明確な用途(テキストスペースが必要な招待状イラスト)、具体的なスタイル参照、雰囲気のコントロール(ロマンチックだが俗っぽくないは非常に正確な美的要求)、あらかじめ設定されたテキスト要素。

避けるべきよくある誤り
誤り1:説明が短すぎて抽象的
「花を描いて」のようなプロンプトは、すべての決定権をAIのランダム生成に委ねることになります。結果はあなたが望むものと全く異なる可能性があります。
誤り2:矛盾した要求
「ミニマリストスタイルで、でも細部が豊富に」——これはAIを困惑させます。指示を出す前に、自分が本当に何を望んでいるのか明確にしましょう。
誤り3:画像の用途を述べるのを忘れる
「カフェ」をモバイル壁紙用にするのと屋外看板用にするのでは、構図が全く異なります。プロンプトで「この画像はソーシャルメディアカバー用、16:9比率」と明確に述べることで、後処理の調整の手間がかなり省けます。
誤り4:一度にあれこれ詰め込みすぎる
「画像には山、海、都市、森、人、動物を入れて……」要素が多すぎると混沌とします。まず核となる主題を決め、他はすべて引き立て役です。
誤り5:スタイル参照を提供しない
「きれいにして」という説明は無意味です。AIはあなたの「きれい」が何を意味するのかわかりません。具体的なスタイル参照——特定のアーティスト、映画、芸術運動——を提供する方が形容詞よりはるかに有用です。
XXAIでGPT-Image-1を体験する
ここまで話してきて、きっとあなたも自分で試したくなったでしょう。XXAIプラットフォームにはすでにGPT-Image-1が統合されており、ここで前述のすべての機能を直接体験できます:
- 自然言語で望む画像を説明する
- さまざまなスタイルの画像を生成する
- 画像内にテキストコンテンツを正確にレンダリングする
デザイン、マーケティング、教育に携わっている方も、単にAIアート生成を探求したい方も、このツールは試す価値があります。
XXAIを開いて、GPT-Image-1を見つけ、頭の中にあるその画像を説明してみてください——AIがそれを実現してくれるか見てみましょう。創作は想像以上に簡単だと気づくかもしれません。