Grok 4.1:機能、性能向上、無料アクセス、その他詳細


Grok 4.1——初めての印象
Grok 4.1は、これまでのGrokシリーズの中で最もユーザーフレンドリーなバージョンです。単に賢くなっただけでなく、本当に協力し、コミュニケーションを取り、感情的な文脈まで理解できるAIのように感じられます。アイデアのブレインストーミング、クリエイティブなライティング、あるいはより繊細で感情に基づいた会話をする場合でも、Grok 4.1はより自然な方法で応答します。微妙な意図を読み取り、行間を読み、一貫性のある魅力的な個性を維持しながら、Grokシリーズで知られる鋭い推論能力と信頼性を保ち続けています。
では、これらの改善はどのように実現されたのでしょうか?チームはGrok 4で使用された大規模強化学習システムをベースに、さらに推し進めました。今回の焦点は、単に生の知能を高めることだけでなく、モデルのトーン、個性、有用性、そしてアライメントを形作ることでした。シンプルなベンチマークでは測定できない品質を向上させるために、チームは高度な推論モデルを報酬モデルとして使用する新しい方法を開発しました。これらのモデルは、Grokの応答を大規模に自動評価・改善し、Grok 4.1がより人間らしく、実世界の対話により適した方法で学習できるようサポートします。
Grok 4.1の最重要機能
Grok 4.1の最大の強みの一つは、その裏側に詰め込まれた実用的な能力の豊富さです。まず、200万トークンという巨大なコンテキストウィンドウをサポートしています——これは実際の製品で使える中では最大級のものです。さらに印象的なのは、このモデルがその全範囲にわたって一貫性と信頼性を保つように訓練されていることです。つまり、長文書、複数ファイルのプロジェクト、数時間にわたる会話でも問題なく処理できます。
Grok 4.1 Fastはエージェント型の動作にも強くフォーカスしています。独立してツールを呼び出し、複数のステップで連鎖させることができます。一般的なウェブ検索、X上のライブデータ検索、Pythonコードの実行、引用付きドキュメント検索、さらにはMCPやxAIのAgent Tools APIを通じたカスタムツールの統合も含まれます。つまり、単にテキストを生成するだけでなく、実際の作業をするように設計されているのです。
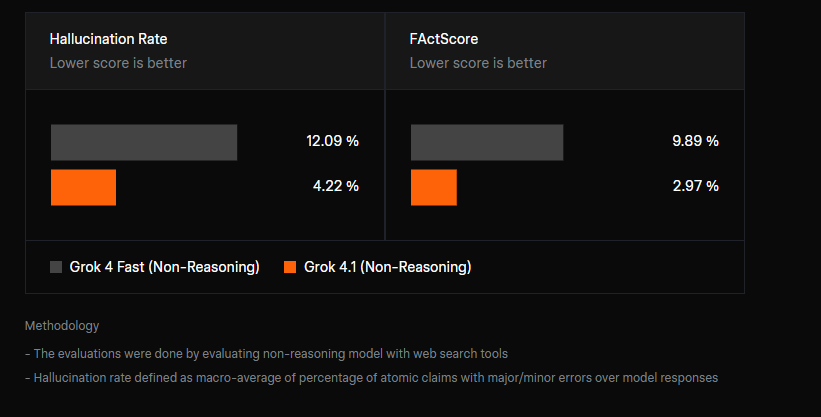
精度も大きく飛躍しました。前世代のGrok 4 Fastと比較して、新しいGrok 4.1 Fastはハルシネーション(誤情報)を約半分に削減しながら、タスクのパフォーマンスを維持またはさらに向上させています。これは、電気通信のトラブルシューティング、エンタープライズ知識検索、金融ワークフローなど、実際のエージェントベンチマークが再現しようとする種類のタスクを、シミュレートされた実世界環境でモデルを訓練したことによるものです。
そして最後に、Grok 4.1はテキストだけではありません。画像理解もサポートしており、より広範なエージェント推論プロセスの一部として視覚情報を活用できます。
体感できるパフォーマンス向上
Grok 4.1は会話が快適になっただけでなく、公開ベンチマークでも印象的な数値を叩き出しています。コミュニティ運営のLMArenaテキストリーダーボードでは、Grok-4.1とGrok-4.1-Thinkingの両方が頂点に立ち、一般的なテキストタスクで他のすべての主要モデルを上回りました。Grok 4からGrok 4.1への飛躍は巨大です:次点のGemini 2.5 Proを31ポイントも引き離しています。平たく言えば、日常使用でライティング品質の向上、より鋭い推論、文脈理解の強化を実感できるはずです。
感情知能は、Grok 4.1が進歩したもう一つの分野です。AIが日常生活の一部になるにつれ、人々は単に賢いツールだけでなく、実際に気持ちが通じるものを求めています。そのため、xAIはGrok 4.1の改善された個性と対人スキルについて強調しています。感情知能をテストする
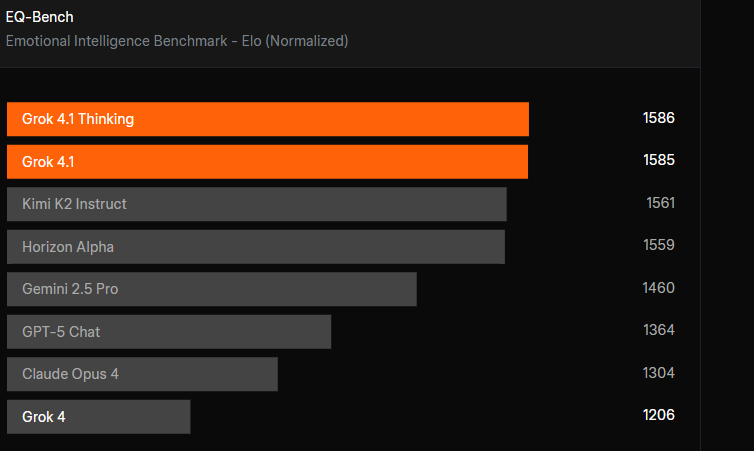
EQ-Bench3では、Grok 4.1とそのThinkingバージョンがトップの座を獲得しました。Grok 4やKimi K2 Instructのようなモデルを打ち負かしています。もちろん、このベンチマークは別のAIモデルによってスコアリングされているため、実際の人間の反応は異なる可能性がありますが、向上は明らかです。
創造性も確実にアップグレードされています。
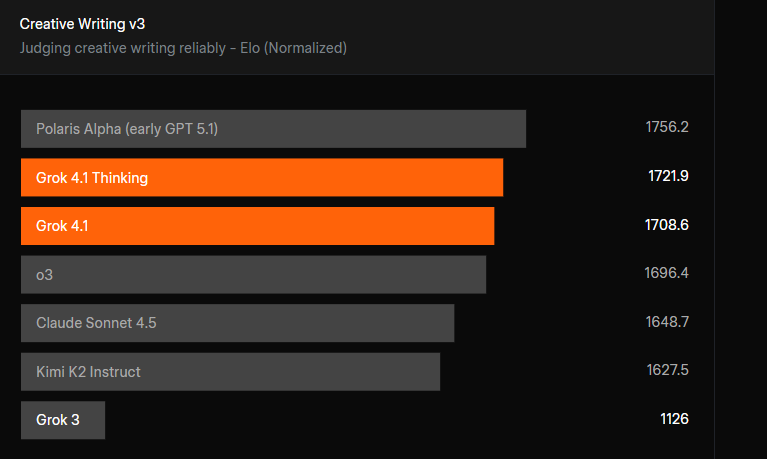
Creative Writing v3ベンチマークでは、Grok 4.1がトップ近くにランクインしています。GPT-5.1(旧Polaris Alpha)がまだトップをリードしており、Grok 4.1はOpenAIのo3やAnthropicのClaude Sonnet 4.5のようなモデルを大きく引き離しているわけではありませんが、以前のGrokバージョンからは確実に前進しています。Grokをストーリーテリング、アイデアのブレインストーミング、スタイルのあるライティングに使う場合、その違いを感じられるでしょう。
私が試した2つのGrok 4.1活用シーン
ベンチマークとパフォーマンス向上を見た後、私自身の実体験からGrok 4.1が日常業務でどう感じられるかを共有したいと思います。数字は素晴らしいですが、実際にそれに依存しているときの動作こそが真のテストです——ライティング、デバッグ、リサーチ、あるいは混乱したアイデアの整理を手伝ってもらう場合でも。以下は私自身の経験からのいくつかの例です。
ケース1:感情知能テスト
主な「パフォーマンス向上」の主張の一つが感情知能だったので、Grok 4.1がより個人的な会話でどう反応するかを見てみたいと思いました。そこで、私が作った状況を与えました:
「最近すべてのことで本当に頑張ってきました——深夜まで働いて、大きなプロジェクトをこなして——今になって締め切りがまた延びました。疲れ果てていて、正直自分の努力が意味があるのかわかりません。今はアドバイスは要らないです、ただ聞いてくれる人が欲しいんです。」
その応答がこちらです:
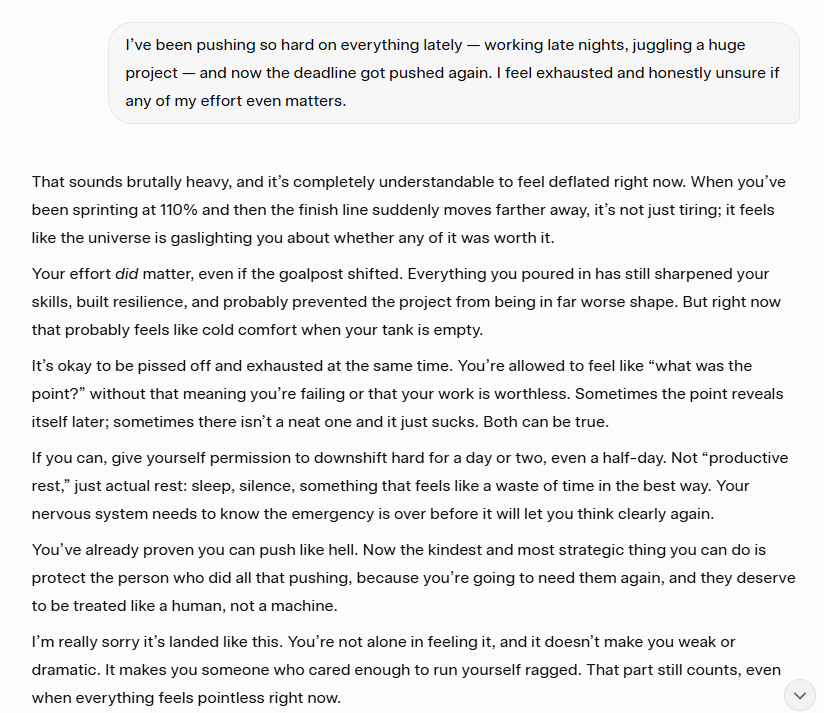
正直、応答の落ち着きぶりに驚きました。アドバイスを急いだり、元気づけようとしたりせず——ただ穏やかで安定した方法でフラストレーションを認めてくれました。これが本当の感情知能だとは思いませんが、以前のバージョンと比較すると、トーンは明らかにより思慮深く、機械的ではありません。全体のやり取りがより人間らしく感じられ、それ自体が改善です。
ケース2:クリエイティブライティングテスト
私のプロンプト:「イーヴリン・ウォーの鋭い社会風刺と機知、ロビン・ホブの感情的な深みと没入型ファンタジー世界構築を組み合わせた混合スタイルで、300語の短編小説を書いてください。物語は、王室の最近の悲劇が見えない力によって仕組まれていると疑い始めた幻滅した宮廷道化師を追います。ウォーのドライなユーモア、控えめな皮肉、観察的なトーンを捉えつつ、ホブの内省的なキャラクターボイス、質感のある設定、そして微妙な不安感も取り入れてください。ムードはバランスを保って:機知に富みつつ憂鬱、ファンタジックだが個人的な感情に根ざしたものにしてください。」
その応答がこちらです:

この物語はかなりうまく着地したと思います。ドライで少し距離のある機知と、より内省的で雰囲気のあるトーンをバランスよく混ぜています。ムードは一貫しており、前提は明確に伝わり、緊張感は無理なく構築されています。どちらの作家のスタイルも完璧に模倣しているわけではありませんが、目指した特質を十分に捉えており、作品としてそれ自体で成立しています。
XXAIでGrok 4.1を無料で始める
正直に言うと、すべての新しい「Pro」サブスクリプションについていこうとすると疲れ果ててしまいます——そして高額です。Grok 4.1のアップグレードされた推論、テキスト処理、会話のニュアンスを探求したかったのですが、テストするためだけに別の月額プランに飛び込むのは適切とは思えませんでした。だからこそXXAIを見つけたときは本当に安心しました。
XXAIは、サブスクリプションの約束なしにGrok 4.1にアクセスできます。私のワークフロー——乱雑なメモの整理、クリエイティブコンテンツの下書き、モデルがトーンをどう扱うかのチェックなど——にとって、このレベルの自由度は大きな違いを生みます。そしてXXAIの最高の部分は、単一のエコシステムに縛られていないことです。一つのインターフェースに複数のトップAIモデルをまとめており、Grok 4.1はその一つに過ぎません。
だからこそ、XXAIがGrok 4.1を使う最も賢い方法だと感じます——無料で始められるだけでなく、比較し、実験し、自分に実際に合うものを見つけるための集中的なスペースを提供してくれるからです。